
前言
数据库本质上是一种共享资源,因此在最大程度提供并发访问性能的同时,仍需要确保每个用户能以一致的方式读取和修改数据。锁机制(Locking)就是解决这类问题的最好武器。
锁分类
从对数据操作的类型分类:
读锁(共享锁):针对同一份数据,多个读操作可以同时进行,不会互相影响写锁(排他锁):当前写操作没有完成前,它会阻断其他写锁和读锁
为了尽可能提高数据库的并发度,每次锁定的数据范围越小越好,但是管理锁是很耗资源的事情(涉及获取,检查,释放锁等动作),因此数据库系统需要在高并发响应和系统性能两方面进行平衡,这样就产生了“锁粒度(Lock granularity)”的概念。
- 表级锁:开销小,加锁快;不会出现死锁;锁定粒度大,发生锁冲突的概率最高,并发度最低(MyISAM 和 MEMORY 存储引擎采用的是表级锁);
- 行级锁:开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度也最高(InnoDB 存储引擎既支持行级锁也支持表级锁,但默认情况下是采用行级锁);
- 页面锁:开销和加锁时间界于表锁和行锁之间;会出现死锁;锁定粒度界于表锁和行锁之间,并发度一般。
从锁的角度来说,表级锁更适合于以查询为主,只有少量按索引条件更新数据的应用,如Web应用;而行级锁则更适合于有大量按索引条件并发更新少量不同数据,同时又有并发查询的应用,如一些在线事务处理(OLTP)系统。
例
首先新建表 test,其中 id 为主键,name 为辅助索引,address 为唯一索引。
INSERT 方法中的行锁
如果两个事务先后对主键相同的行记录执行 INSERT 操作,因为事务 A 先拿到了行锁,事务 B 只能等待直到事务 A 提交后行锁被释放。同理,如果针对唯一索引字段 address 进行插入操作,也需要获取行锁,图同主键插入过程类似,不再重复。
但是,如果两个事务都针对辅助索引字段 name 进行插入,不需要等待获取锁,因为辅助索引字段即使值相同,在数据库中也是操作不同的记录行,不会冲突。
Update 方法与 Insert 方法结果类似。
SELECT FOR UPDATE 下的表锁与行锁
事务 A SELECT FOR UPDATE 语句会拿到表 test 的 Table Lock,此时事务 B 去执行插入操作会阻塞,直到事务 A 提交释放表锁后,事务 B 才能获取对应的行锁执行插入操作。
但是如果事务 A 的 SELECT FOR UPDATE 语句紧跟 WHERE id = 1 的话,那么这条语句只会获取行锁,不会是表锁,此时不阻塞事务 B 对于其他主键的修改操作。
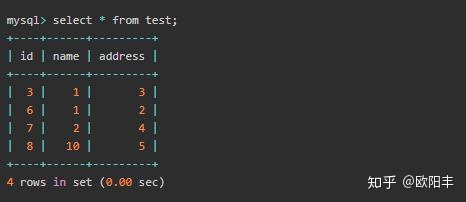
辅助索引下的间隙锁
先看下 test 表下的数据情况:
间隙锁可以说是行锁的一种,不同的是它锁住的是一个范围内的记录,作用是避免幻读,即区间数据条目的突然增减。解决办法主要是:
- 防止间隙内有新数据被插入,因此叫间隙锁
- 防止已存在的数据,在更新操作后成为间隙内的数据(例如更新 id = 7 的 name 字段为 1,那么 name = 1 的条数就从 2 变为 3)
InnoDB 自动使用间隙锁的条件为:
- Repeatable Read 隔离级别,这是 MySQL 的默认工作级别
- 检索条件必须有索引(没有索引的话会走全表扫描,那样会锁定整张表所有的记录)
当 InnoDB 扫描索引记录的时候,会首先对选中的索引行记录加上行锁,再对索引记录两边的间隙(向左扫描扫到第一个比给定参数小的值, 向右扫描扫描到第一个比给定参数大的值, 以此构建一个区间)加上间隙锁。如果一个间隙被事务 A 加了锁,事务 B 是不能在这个间隙插入记录的。
我们这里所说的 “间隙锁” 其实不是 GAP LOCK,而是 RECORD LOCK + GAP LOCK,InnoDB 中称之为 NEXT_KEY LOCK。
下面看个例子,我们建表时指定 name 列为辅助索引,目前这列的取值有 [1,2,10]。间隙范围有 (-∞, 1]、[1,1]、[1,2]、[2,10]、[10, +∞)
Round 1:
事务 A SELECT … WHERE name = 1 FOR UPDATE;
对 (-∞, 2) 增加间隙锁
- 事务 B INSERT … name = 1 阻塞
- 事务 B INSERT … name = -100 阻塞
- 事务 B INSERT … name = 2 成功
- 事务 B INSERT … name = 3 成功
Round 2:
事务 A SELECT … WHERE name = 2 FOR UPDATE;
对 [1, 10) 增加间隙锁
- 事务 B INSERT … name = 1 阻塞
- 事务 B INSERT … name = 9 阻塞
- 事务 B INSERT … name = 10 成功
- 事务 B INSERT … name = 0 成功
Round 3:
事务 A SELECT … WHERE name <= 2 FOR UPDATE;
对 (-∞, +∞) 增加间隙锁
- 事务 B INSERT … name = 3 阻塞
- 事务 B INSERT … name = 300 阻塞
- 事务 B INSERT … name = -300 阻塞
死锁
死锁是指两个或多个事务在同一资源上相互占用,并请求锁定对方占用的资源,从而导致恶性循环。
死锁有双重原因:真正的数据冲突;存储引擎的实现方式。
检测死锁:数据库系统实现了各种死锁检测和死锁超时的机制。InnoDB存储引擎能检测到死锁的循环依赖并立即返回一个错误。
死锁恢复:死锁发生以后,只有部分或完全回滚其中一个事务,才能打破死锁,InnoDB目前处理死锁的方法是,将持有最少行级排他锁的事务进行回滚。
外部锁的死锁检测:发生死锁后,InnoDB 一般都能自动检测到,并使一个事务释放锁并回退,另一个事务获得锁,继续完成事务。但在涉及外部锁,或涉及表锁的情况下,InnoDB 并不能完全自动检测到死锁, 这需要通过设置锁等待超时参数 innodb_lock_wait_timeout 来解决
死锁影响性能:死锁会影响性能而不是会产生严重错误,因为InnoDB会自动检测死锁状况并回滚其中一个受影响的事务。在高并发系统上,当许多线程等待同一个锁时,死锁检测可能导致速度变慢。有时当发生死锁时,禁用死锁检测(使用innodb_deadlock_detect配置选项)可能会更有效,这时可以依赖innodb_lock_wait_timeout设置进行事务回滚。
InnoDB避免死锁:
- 为了在单个InnoDB表上执行多个并发写入操作时避免死锁,可以在事务开始时通过为预期要修改的每个元祖(行)使用SELECT … FOR UPDATE语句来获取必要的锁,即使这些行的更改语句是在之后才执行的。
- 在事务中,如果要更新记录,应该直接申请足够级别的锁,即排他锁,而不应先申请共享锁、更新时再申请排他锁,因为这时候当用户再申请排他锁时,其他事务可能又已经获得了相同记录的共享锁,从而造成锁冲突,甚至死锁
- 如果事务需要修改或锁定多个表,则应在每个事务中以相同的顺序使用加锁语句。在应用中,如果不同的程序会并发存取多个表,应尽量约定以相同的顺序来访问表,这样可以大大降低产生死锁的机会
- 通过SELECT … LOCK IN SHARE MODE获取行的读锁后,如果当前事务再需要对该记录进行更新操作,则很有可能造成死锁。
- 改变事务隔离级别
如果出现死锁,可以用 show engine innodb status;命令来确定最后一个死锁产生的原因。返回结果中包括死锁相关事务的详细信息,如引发死锁的 SQL 语句,事务已经获得的锁,正在等待什么锁,以及被回滚的事务等。据此可以分析死锁产生的原因和改进措施。