
前言
Redis 是 C 语言开发的一个开源的高性能键值对(key-value)的NoSQL内存数据库,可以用作数据库、缓存、消息中间件等。
优点:
速度快(每秒10万次读写)、多种数据结构、支持多种客户端语言、功能丰富、支持集群分布式。
缺点:
成本高昂(消耗cpu、内存)、持久化影响性能。
使用场景
- 缓存系统
缓存是Redis最常见的应用场景,之所有这么使用,主要是因为Redis读写性能优异。而且逐渐有取代memcached,成为首选服务端缓存的组件。而且,Redis内部是支持事务的,在使用时候能有效保证数据的一致性。
- 丰富的数据格式性能更高,应用场景丰富
Redis相比其他缓存,有一个非常大的优势,就是支持多种数据类型。
- string——适合最简单的k-v存储,类似于memcached的存储结构,短信验证码,配置信息等,就用这种类型来存储。
- hash——一般key为ID或者唯一标示,value对应的就是详情了。如商品详情,个人信息详情,新闻详情等。
- list——因为list是有序的,比较适合存储一些有序且数据相对固定的数据。如省市区表、字典表等。因为list是有序的,适合根据写入的时间来排序,如:最新的***,消息队列等。
- set——可以简单的理解为ID-List的模式,如微博中一个人有哪些好友,set最牛的地方在于,可以对两个set提供交集、并集、差集操作。例如:查找两个人共同的好友等。
- Sorted Set——是set的增强版本,增加了一个score参数,自动会根据score的值进行排序。比较适合类似于top 10等不根据插入的时间来排序的数据。
- 作为分布式锁
redis支持setnx操作(即key不存在的情况下设置value),这种特性常用来做分布式锁的实现。
- 过期时间设置
最常见的就是:短信验证码、具有时间性的商品展示等。无需像数据库还要去查时间进行对比。因为使用比较简单,就不赘述了。
通信
TCP协议
Redis底层网络通信协议其实是通过TCP来完成的。
RESP协议。
Redis客户端和服务器端使用的序列化协议,它是特意为Redis设计的,同时也可以用于其他软件工程。
RESP可以序列化多种不同的数据类型,比如:整型、字符串、数组。错误是一种特定的类型。Redis客户端把参数用数组来表示。回复的是一种特殊的数据格式。
pipeline管道
pipeline管道就是解决执行大量命令时、会产生大量数据来回次数而导致延迟的技术。其实原理比较简单,pipeline是把所有的命令一次发过去,避免频繁的发送、接收带来的网络开销,redis在打包接收到一堆命令后,依次执行,然后把结果再打包返回给客户端。
单线程
redis虽然是单线程,却是直接操作内存,同时使用了IO多路复用,异步非阻塞,效率依然可观。
请求处理过程
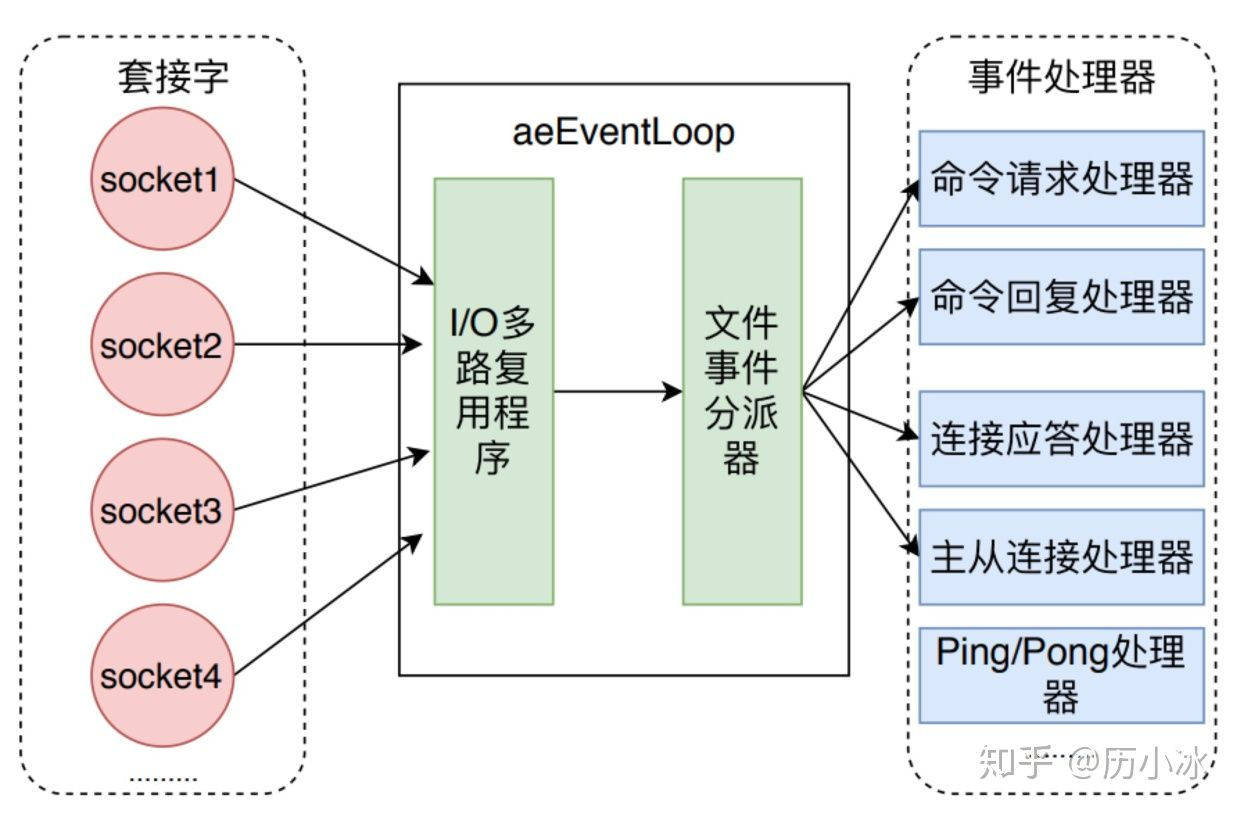
可以看到整个请求过程操作都离不开文本事件处理器
当Redis启动时,在所监听的 socket 上 创建文件事件处理器,监听 socket 建立连接的事件。
当用户在客户端中键入一个命令请求时, 客户端会将这个命令请求转换成协议格式(RESP), 然后建立到服务器的socket,建立client,注册socket读取事件处理器,将协议格式的命令请求发送给服务器(读取事件处理器)。
服务器端读取套接字中协议格式的命令请求, 并将其保存到客户端状态的输入缓冲区里面。
对输入缓冲区中的命令请求进行分析, 提取出命令请求中包含的命令参数, 以及命令参数的个数, 然后分别将参数和参数个数保存到客户端状态的 argv 属性和 argc 属性里面。
调用命令执行器, 执行客户端指定的命令,命令实现函数会将命令回复保存到客户端的输出缓冲区里面。
注册socket写入事件处理器,从输入缓冲区写回数据到socket,关闭client,清空缓冲区。
IO多路复用模型
多路I/O复用模型是利用 select、poll、epoll 可以同时监察多个流的 I/O 事件的能力,在空闲的时候,会把当前线程阻塞掉,当有一个或多个流有 I/O 事件时,就从阻塞态中唤醒,于是程序就会轮询一遍所有的流(epoll 是只轮询那些真正发出了事件的流),并且只依次顺序的处理就绪的流,这种做法就避免了大量的无用操作。
在 I/O 多路复用模型中,最重要的函数调用就是 select,该方法的能够同时监控多个文件描述符的可读可写情况,当其中的某些文件描述符可读或者可写时,select 方法就会返回可读以及可写的文件描述符个数。
Redis 服务采用 Reactor 的方式来实现文件事件处理器(每一个网络连接其实都对应一个文件描述符)
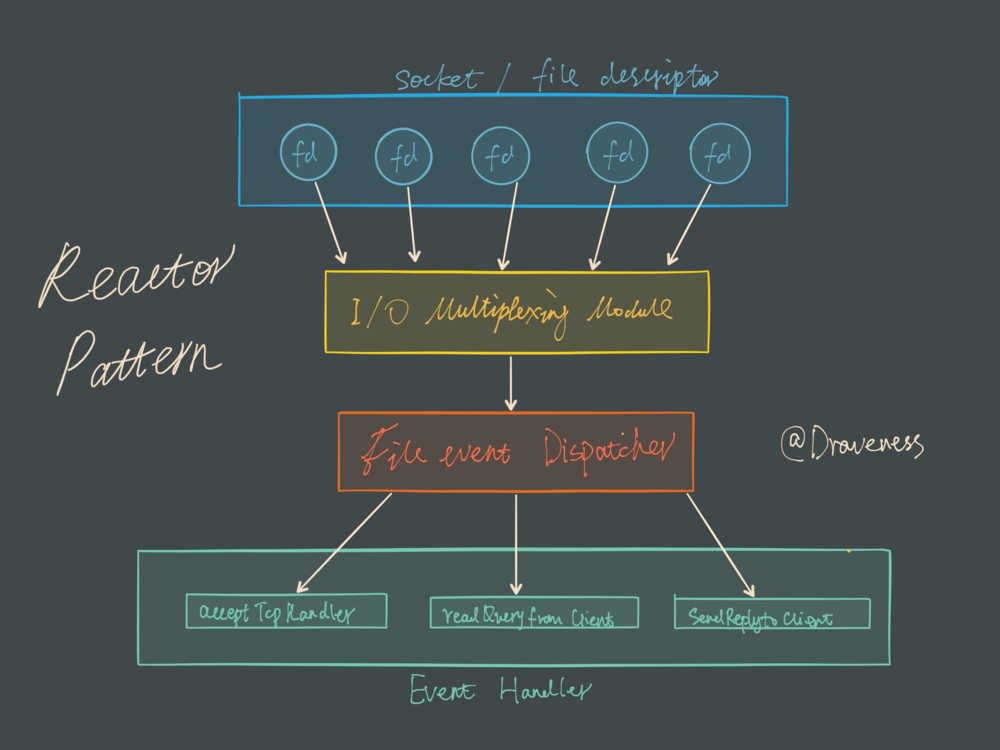
文件事件处理器使用 I/O 多路复用模块同时监听多个 FD,当 accept、read、write 和 close 文件事件产生时,文件事件处理器就会回调 FD 绑定的事件处理器。
虽然整个文件事件处理器是在单线程上运行的,但是通过 I/O 多路复用模块的引入,实现了同时对多个 FD 读写的监控,提高了网络通信模型的性能,同时也可以保证整个 Redis 服务实现的简单。
基础数据结构
redis提供了多种数据结构,我们主要了解其中五种基础数据结构:String、Hash、List、Set、Sorted Set。
Redis 的 key 是字符串类型,但是 key 中不能包括边界字符,由于 key 不是 binary safe
的字符串,所以像”my key”和”mykey\n”这样包含空格和换行的 key 是不允许的。
首先redis内部使用一个redisObject对象来表示所有的key和value.
1 | typedef struct redisObject { |
简单介绍一下这几个字段:
- type:数据类型,就是我们熟悉的string、hash、list等。
- encoding:内部编码,其实就是本文要介绍的数据结构。指的是当前这个value底层是用的什么数据结构。因为同一个数据类型底层也有多种数据结构的实现,所以这里需要指定数据结构。
- REDIS_LRU_BITS:当前对象可以保留的时长。这个我们在后面讲键的过期策略的时候讲。
- refcount:对象引用计数,用于GC。
- ptr:指针,指向以encoding的方式实现这个对象的实际地址。
String(字符串)
应用场景:
存储key-value键值对,这个比较简单不细说了
list(列表)
应用场景:
由于list它是一个按照插入顺序排序的列表,所以应用场景相对还较多的,例如:
- 消息队列:lpop和rpush(或者反过来,lpush和rpop)能实现队列的功能
- 朋友圈的点赞列表、评论列表、排行榜:lpush命令和lrange命令能实现最新列表的功能,每次通过lpush命令往列表里插入新的元素,然后通过lrange命令读取最新的元素列表。
hash (字典)
应用场景:
- 购物车:hset [key] [field] [value] 命令, 可以实现以用户Id,商品Id为field,商品数量为value,恰好构成了购物车的3个要素。
- 存储对象:hash类型的(key, field, value)的结构与对象的(对象id, 属性, 值)的结构相似,也可以用来存储对象。
set(集合)
应用场景:
- 好友、关注、粉丝、感兴趣的人集合:
- 首页展示随机:美团首页有很多推荐商家,但是并不能全部展示,set类型适合存放所有需要展示的内容,而srandmember命令则可以从中随机获取几个。
- 存储某活动中中奖的用户ID ,因为有去重功能,可以保证同一个用户不会中奖两次。
zset(有序集合)
应用场景:
- zset 可以用做排行榜,但是和list不同的是zset它能够实现动态的排序,例如: 可以用来存储粉丝列表,value 值是粉丝的用户 ID,score 是关注时间,我们可以对粉丝列表按关注时间进行排序。
- zset 还可以用来存储学生的成绩, value 值是学生的 ID, score 是他的考试成绩。 我们对成绩按分数进行排序就可以得到他的名次。
客户端
目前主流的客户端有三种,Jedis、Lettuce、Redisson,我们从几个方面比较以下它们。
性能
Jedis的性能比lettuce和Redisson都要差一点,三者的主要差异在于以下:
Jedis使用同步和阻塞IO的方式,不支持异步;lettuce和Redisson支持异步,底层是基于netty框架的事件驱动作为通信层。
Jedis设计上就是基于线程不安全来设计,一个连接只能被一个线程使用,但是可以结合连接池来提高其性能;lettuce和Redis基于线程安全来设计的,一个连接是被共享使用的,但是也提供了连接池,主要用于事务以及阻塞操作的命令。
lettuce和Redisson支持异步流的方式。
功能
Jedis: 提供比较全面的redis原生指令的支持,上层封装比较弱,集群特性支持度非常低,高级特性几乎没有。
lettuce: 高级redis客户端,支持各种模式的redis连接和操作,高级特性几乎没有。
Redisson: 高级redis客户端,支持各种模式的redis连接和操作,同时提供一大堆的实用功能。
Redisson
Redisson支持了很多高级功能:分布式锁、事务、RPC、分布式任务调度等;
实际上单是使用Redisson作为Spring的客户端就足够了。但是Redisson实际上对字符串操作支持性差。
个人倾向lettuce,如果需要分布式锁、分布式集合等分布式高级特性可以结合 Redisson 使用。