概述 spring2x版本,提供了注解配置的方式,本文会基于注解的方向分析SpringIOC模块的整体流程。
主要关注注解方式启动spring与xml配置方式有何变化?
demo 1 2 3 4 5 6 7 public class AnnotationIOCDemo public static void main (String args[]) ApplicationContext context = new AnnotationConfigApplicationContext("cn.shiyujun.config" ); IOCService iocService=context.getBean(IOCService.class ) ; System.out.println(iocService.hollo()); } }
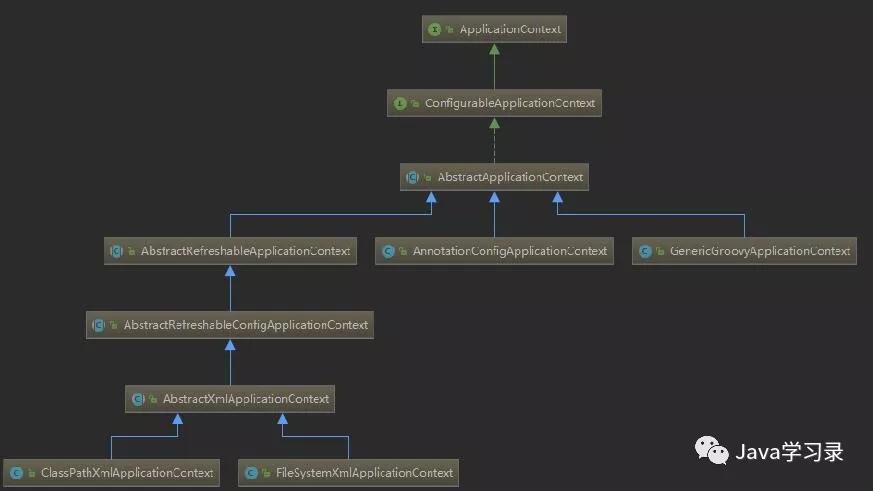
AnnotationConfigApplicationContext 继承关系
可以看到相较于 ClassPathXmlApplicationContext 和 FileSystemXmlApplicationContext 来说AnnotationConfigApplicationContext 这个类的辈分好像更高一些
源码分析 1 2 3 4 5 public AnnotationConfigApplicationContext (String... basePackages) this (); scan(basePackages); refresh(); }
这里能看出与 ClassPathXmlApplicationContext 有很多不一样的地方了。
this() 首先看this:
1 2 3 4 5 6 public AnnotationConfigApplicationContext () this .reader = new AnnotatedBeanDefinitionReader(this ); this .scanner = new ClassPathBeanDefinitionScanner(this ); }
AnnotatedBeanDefinitionReader, ClassPathBeanDefinitionScanner这两个核心类比较重要。
AnnotatedBeanDefinitionReader 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 public AnnotatedBeanDefinitionReader (BeanDefinitionRegistry registry, Environment environment) Assert.notNull(registry, "BeanDefinitionRegistry must not be null" ); Assert.notNull(environment, "Environment must not be null" ); this .registry = registry; this .conditionEvaluator = new ConditionEvaluator(registry, environment, null ); AnnotationConfigUtils.registerAnnotationConfigProcessors(this .registry); }
看到这里应该联想到想到 XmlBeanDefinitionReader
AnnotationConfigUtils.registerAnnotationConfigProcessors(this.registry)会把一些自动注解处理器加入到AnnotationConfigApplicationContext下的BeanFactory的BeanDefinitions中
ClassPathBeanDefinitionScanner 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 public ClassPathBeanDefinitionScanner (BeanDefinitionRegistry registry, boolean useDefaultFilters, Environment environment, ResourceLoader resourceLoader) Assert.notNull(registry, "BeanDefinitionRegistry must not be null" ); this .registry = registry; if (useDefaultFilters) { registerDefaultFilters(); } setEnvironment(environment); setResourceLoader(resourceLoader); }
配置扫描过滤,设置环境变量,加载资源文件。
GenericApplicationContext 我们还记得 ClassPathXmlApplicationContext 的父类 AbstractXmlApplicationContext 吗?
与 GenericApplicationContext 有何区别?
子类的构造方法执行之前肯定会先执行父类的构造方法:
1 public class AnnotationConfigApplicationContext extends GenericApplicationContext implements AnnotationConfigRegistry
1 2 3 4 public GenericApplicationContext () this .beanFactory = new DefaultListableBeanFactory(); }
DefaultListableBeanFactory 这个背景强大的类是不是很熟悉。。。
scan() 接着看 scan 方法:
1 2 3 4 public void scan (String... basePackages) Assert.notEmpty(basePackages, "At least one base package must be specified" ); this .scanner.scan(basePackages); }
啊啊,这里就可以看到这里调用的是this 注解的bean扫描器 ClassPathBeanDefinitionScanner 的scan 方法。
1 2 3 4 5 6 7 8 9 10 11 12 13 public int scan (String... basePackages) int beanCountAtScanStart = this .registry.getBeanDefinitionCount(); doScan(basePackages); if (this .includeAnnotationConfig) { AnnotationConfigUtils.registerAnnotationConfigProcessors(this .registry); } return (this .registry.getBeanDefinitionCount() - beanCountAtScanStart); }
接着往下看 doScan 方法。
doScan() 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 Set<BeanDefinitionHolder> doScan (String... basePackages) { Assert.notEmpty(basePackages, "At least one base package must be specified" ); Set<BeanDefinitionHolder> beanDefinitions = new LinkedHashSet<>(); for (String basePackage : basePackages) { Set<BeanDefinition> candidates = findCandidateComponents(basePackage); for (BeanDefinition candidate : candidates) { ScopeMetadata scopeMetadata = this .scopeMetadataResolver.resolveScopeMetadata(candidate); candidate.setScope(scopeMetadata.getScopeName()); String beanName = this .beanNameGenerator.generateBeanName(candidate, this .registry); if (candidate instanceof AbstractBeanDefinition) { postProcessBeanDefinition((AbstractBeanDefinition) candidate, beanName); } if (candidate instanceof AnnotatedBeanDefinition) { AnnotationConfigUtils.processCommonDefinitionAnnotations((AnnotatedBeanDefinition) candidate); } if (checkCandidate(beanName, candidate)) { BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder(candidate, beanName); definitionHolder = AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this .registry); beanDefinitions.add(definitionHolder); registerBeanDefinition(definitionHolder, this .registry); } } } return beanDefinitions;
再来看它扫描包的方法 findCandidateComponents
扫描包 findCandidateComponents() 这个方法判断忽略了Filter指定包不扫描
1 2 3 4 5 6 7 8 9 public Set<BeanDefinition> findCandidateComponents (String basePackage) if (this .componentsIndex != null && indexSupportsIncludeFilters()) { return addCandidateComponentsFromIndex(this .componentsIndex, basePackage); } else { return scanCandidateComponents(basePackage); }
所以还要进入 scanCandidateComponents 方法看一下,不过之前我们有必要先认识一个接口 MetadataReader
根据扫描包反射生成的元数据接口
1 2 3 4 5 6 7 8 9 public interface MetadataReader Resource getResource () ; ClassMetadata getClassMetadata () ; AnnotationMetadata getAnnotationMetadata () ; }
第一个返回Resource就不必多说了,就是配置类的资源对象。第二个第三个根据名字我们可以猜到是类的元数据和注解的元数据 可以看一下它们两个的方法。
scanCandidateComponents() 这个方法就很清晰了:
组装扫描路径
遍历根据路径获取资源对象数组
根据反射生成的元数据是否有@Conditional一系列的注解,然后是否满足注册Bean的条件
满足Bean的条件,用 ScannedGenericBeanDefinition 类去组装他,存入 BeanDefinition 的Set集合。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 private Set<BeanDefinition> scanCandidateComponents (String basePackage) Set<BeanDefinition> candidates = new LinkedHashSet<>(); try { String packageSearchPath = ResourcePatternResolver.CLASSPATH_ALL_URL_PREFIX + resolveBasePackage(basePackage) + '/' + this .resourcePattern; Resource[] resources = getResourcePatternResolver().getResources(packageSearchPath); boolean traceEnabled = logger.isTraceEnabled(); boolean debugEnabled = logger.isDebugEnabled(); for (Resource resource : resources) { if (traceEnabled) { logger.trace("Scanning " + resource); } if (resource.isReadable()) { try { MetadataReader metadataReader = getMetadataReaderFactory().getMetadataReader(resource); if (isCandidateComponent(metadataReader)) { ScannedGenericBeanDefinition sbd = new ScannedGenericBeanDefinition(metadataReader); sbd.setResource(resource); sbd.setSource(resource); if (isCandidateComponent(sbd)) { if (debugEnabled) { logger.debug("Identified candidate component class: " + resource); } candidates.add(sbd); } else { if (debugEnabled) { logger.debug("Ignored because not a concrete top-level class: " + resource); } } } else { if (traceEnabled) { logger.trace("Ignored because not matching any filter: " + resource); } } } catch (Throwable ex) { throw new BeanDefinitionStoreException( "Failed to read candidate component class: " + resource, ex); } } else { if (traceEnabled) { logger.trace("Ignored because not readable: " + resource); } } } } catch (IOException ex) { throw new BeanDefinitionStoreException("I/O failure during classpath scanning" , ex); } return candidates; }
我们发现这里就已经出现了 BeanDifinition,上文xml配置启动我们是在refresh()方法。。。
创建 BeanDefinition 让我们回到 doScan() 方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 protected Set<BeanDefinitionHolder> doScan (String... basePackages) Assert.notEmpty(basePackages, "At least one base package must be specified" ); Set<BeanDefinitionHolder> beanDefinitions = new LinkedHashSet<>(); for (String basePackage : basePackages) { Set<BeanDefinition> candidates = findCandidateComponents(basePackage); for (BeanDefinition candidate : candidates) { ScopeMetadata scopeMetadata = this .scopeMetadataResolver.resolveScopeMetadata(candidate); candidate.setScope(scopeMetadata.getScopeName()); String beanName = this .beanNameGenerator.generateBeanName(candidate, this .registry); if (candidate instanceof AbstractBeanDefinition) { postProcessBeanDefinition((AbstractBeanDefinition) candidate, beanName); } if (candidate instanceof AnnotatedBeanDefinition) { AnnotationConfigUtils.processCommonDefinitionAnnotations((AnnotatedBeanDefinition) candidate); } if (checkCandidate(beanName, candidate)) { BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder(candidate, beanName); definitionHolder = AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this .registry); beanDefinitions.add(definitionHolder); registerBeanDefinition(definitionHolder, this .registry); } } } return beanDefinitions; }
我们又把 Set<BeanDefinition> 里的数据进行一番处理后又存入 Set<BeanDefinitionHolder>。 接下来我们来看一下 registerBeanDefinition 方法
注册 Bean 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 protected void registerBeanDefinition (BeanDefinitionHolder definitionHolder, BeanDefinitionRegistry registry) BeanDefinitionReaderUtils.registerBeanDefinition(definitionHolder, registry); } public static void registerBeanDefinition ( BeanDefinitionHolder definitionHolder, BeanDefinitionRegistry registry) throws BeanDefinitionStoreException String beanName = definitionHolder.getBeanName(); registry.registerBeanDefinition(beanName, definitionHolder.getBeanDefinition()); String[] aliases = definitionHolder.getAliases(); if (aliases != null ) { for (String alias: aliases) { registry.registerAlias(beanName, alias); } } }
其实这个注册bean的方法是DefaultListableBeanFactory的方法,之前的文章已经解析过了,最终会将注册了的 BeanDefinition 存入 beanDefinitionMap这里就很明白了:
相对与xml配置的方式,注解式将创建bean,注解bean的过程放在 scan() 里执行
那我们再看看 refresh 方法。。。
refresh() 首先整个方法进来以后跟使用XML的时候是一样的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 public void refresh () throws BeansException, IllegalStateException synchronized (this .startupShutdownMonitor) { prepareRefresh(); ConfigurableListableBeanFactory beanFactory = obtainFreshBeanFactory(); prepareBeanFactory(beanFactory); try { postProcessBeanFactory(beanFactory); invokeBeanFactoryPostProcessors(beanFactory); registerBeanPostProcessors(beanFactory); initMessageSource(); initApplicationEventMulticaster(); onRefresh(); registerListeners(); finishBeanFactoryInitialization(beanFactory); finishRefresh(); } catch (BeansException ex) { if (logger.isWarnEnabled()) { logger.warn("Exception encountered during context initialization - " + "cancelling refresh attempt: " + ex); } destroyBeans(); cancelRefresh(ex); throw ex; } finally { resetCommonCaches(); } } }
与xml不同 其实之前的解析xml、创建Bean、注册Bean都是在 obtainFreshBeanFactory 方法进行,我们花了好长的时间去解析,现在再看注解式它的源码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 protected ConfigurableListableBeanFactory obtainFreshBeanFactory () refreshBeanFactory(); ConfigurableListableBeanFactory beanFactory = getBeanFactory(); if (logger.isDebugEnabled()) { logger.debug("Bean factory for " + getDisplayName() + ": " + beanFactory); } return beanFactory; } protected final void refreshBeanFactory () throws IllegalStateException if (!this .refreshed.compareAndSet(false , true )) { throw new IllegalStateException( "GenericApplicationContext does not support multiple refresh attempts: just call 'refresh' once" ); } this .beanFactory.setSerializationId(getId()); }
它的核心方法 refreshBeanFactory 只有这么点了,它来自 GenericApplicationContext 类,是我们的 AnnotationConfigApplicationContext的父类,在对比下 ClassPathXmlApplicationContext 。
1 public class ClassPathXmlApplicationContext extends AbstractXmlApplicationContext
1 public class AnnotationConfigApplicationContext extends GenericApplicationContext implements AnnotationConfigRegistry
refreshBeanFactory 是 AbstractApplicationContext 类的抽象方法,
GenericApplicationContext 与 AbstractRefreshableApplicationContext 分别重写了这个方法,而这两个类分别是 AnnotationConfigApplicationContext 和 ClassPathXmlApplicationContext 的父类和超父类
初始化 初始化就和xml配置一样了,就不赘述了。
思考 我们在日常开发中有时候xml配置和注解是通用的,比如我们在xml里配置扫描:
1 <context:component-scan base-package ="com.qn" />
我们还记得在上篇文章中的一个类:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 protected void parseBeanDefinitions (Element root, BeanDefinitionParserDelegate delegate) if (delegate.isDefaultNamespace(root)) { NodeList nl = root.getChildNodes(); for (int i = 0 ; i < nl.getLength(); i++) { Node node = nl.item(i); if (node instanceof Element) { Element ele = (Element) node; if (delegate.isDefaultNamespace(ele)) { parseDefaultElement(ele, delegate); } else { delegate.parseCustomElement(ele); } } } } else { delegate.parseCustomElement(root); } }
context 标签会走进 parseCustomElement 方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 @Nullable public BeanDefinition parseCustomElement (Element ele, @Nullable BeanDefinition containingBd) String namespaceUri = this .getNamespaceURI(ele); if (namespaceUri == null ) { return null ; } else { NamespaceHandler handler = this .readerContext.getNamespaceHandlerResolver().resolve(namespaceUri); if (handler == null ) { this .error("Unable to locate Spring NamespaceHandler for XML schema namespace [" + namespaceUri + "]" , ele); return null ; } else { return handler.parse(ele, new ParserContext(this .readerContext, this , containingBd)); } } }
它最终会走进parse方法:
1 2 3 4 5 @Nullable public BeanDefinition parse (Element element, ParserContext parserContext) BeanDefinitionParser parser = this .findParserForElement(element, parserContext); return parser != null ? parser.parse(element, parserContext) : null ; }
接着走:
1 2 3 4 5 6 7 8 9 10 @Nullable public BeanDefinition parse (Element element, ParserContext parserContext) String basePackage = element.getAttribute("base-package" ); basePackage = parserContext.getReaderContext().getEnvironment().resolvePlaceholders(basePackage); String[] basePackages = StringUtils.tokenizeToStringArray(basePackage, ",; \t\n" ); ClassPathBeanDefinitionScanner scanner = this .configureScanner(parserContext, element); Set<BeanDefinitionHolder> beanDefinitions = scanner.doScan(basePackages); this .registerComponents(parserContext.getReaderContext(), beanDefinitions, element); return null ; }
Set<BeanDefinitionHolder> 是不是很熟悉, scanner.doScan(basePackages) 是不是很熟悉。。。
参考文档 SpringIOC源码解析(基于注解)