
前言
随着高并发的压力,数据库很容易出现瓶颈:
- 单个库数据量太大;考虑多个库解决问题。
- 单个数据库服务器压力过大、读写瓶颈;考虑多个库、读写分离解决问题。
- 单个表数据量过大;考虑分表解决问题。
分库和切库
对数据库的操作中读多写少,且读操作占用系统资源多,耗时长,适用多个分库进行负载均衡。
它们都是底层是多个数据库在提供服务。
分库是属于在微服务应用拆分的时候都有自己的数据库。
切库是在没有进行应用拆分的时候就已经分成两个库了,根据业务使用不同的代码连接不同的数据库。
实现:
SpringBoot+SpringAOP+Java 自定义注解+mybatis 实现切库读写分离
分表
一张表的数据量很大,即使我们进行了一系列 sql 优化之后依然效率很低,我们就要考虑将它的数据进行分表。
水平切割
水平切割分为库内分表和分库分表,是根据表内数据内在的逻辑关系,将同一个表按不同的条件分散到多个数据库或多个表中,每个表中只包含一部分数据,从而使得单个表的数据量变小,达到分布式的效果。
水平分割优点
不存在单库数据量过大、高并发的性能瓶颈,提升系统稳定性和负载能力
应用端改造较小,不需要拆分业务模块
水平分割缺点
跨分片的事务一致性难以保证
跨库的 join 关联查询性能较差
数据多次扩展难度和维护量极大
数据分片规则
- 根据数值范围
按照时间区间或 ID 区间来切分。例如:按日期将不同月甚至是日的数据分散到不同的库中;将 userId 为 19999 的记录分到第一个库,1000020000 的分到第二个库,以此类推。某种意义上,某些系统中使用的”冷热数据分离”,将一些使用较少的历史数据迁移到其他库中,业务功能上只提供热点数据的查询,也是类似的实践。
这样的优点在于:
- 单表大小可控
- 天然便于水平扩展,后期如果想对整个分片集群扩容时,只需要添加节点即可,无需对其他分片的数据进行迁移
- 使用分片字段进行范围查找时,连续分片可快速定位分片进行快速查询,有效避免跨分片查询的问题。
缺点:
- 热点数据成为性能瓶颈。连续分片可能存在数据热点,例如按时间字段分片,有些分片存储最近时间段内的数据,可能会被频繁的读写,而有些分片存储的历史数据,则很少被查询
- 根据数值取模
一般采用 hash 取模 mod 的切分方式,例如:将 Customer 表根据 cusno 字段切分到 4 个库中,余数为 0 的放到第一个库,余数为 1 的放到第二个库,以此类推。这样同一个用户的数据会分散到同一个库中,如果查询条件带有 cusno 字段,则可明确定位到相应库去查询。
优点:
- 数据分片相对比较均匀,不容易出现热点和并发访问的瓶颈
缺点:
- 后期分片集群扩容时,需要迁移旧的数据(使用一致性 hash 算法能较好的避免这个问题)
- 容易面临跨分片查询的复杂问题。比如上例中,如果频繁用到的查询条件中不带 cusno 时,将会导致无法定位数据库,从而需要同时向 4 个库发起查询,再在内存中合并数据,取最小集返回给应用,分库反而成为拖累。
实现
spring+mybatis 的插件【shardbatis2.0】+mysql+java 自定义注解实现分表
垂直切割
垂直分表是基于数据库中的”列”进行,某个表字段较多,可以新建一张扩展表,将不经常用或字段长度较大的字段拆分出去到扩展表中。在字段很多的情况下(例如一个大表有 100 多个字段),通过”大表拆小表”,更便于开发与维护,也能避免跨页问题
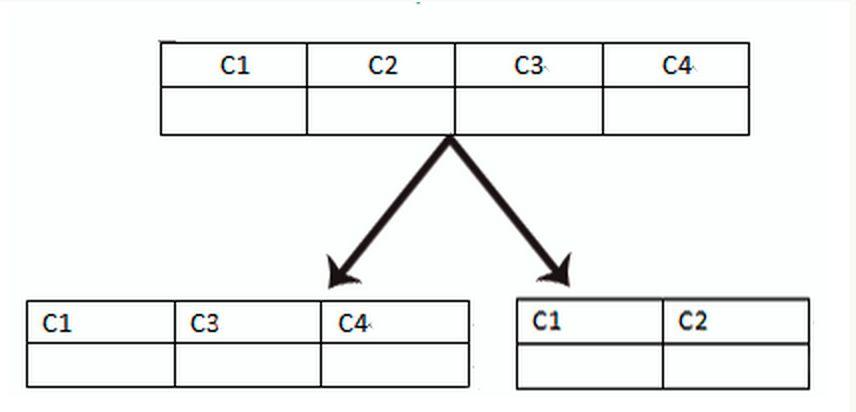
垂直切割优点
解决业务系统层面的耦合,业务清晰
与微服务的治理类似,也能对不同业务的数据进行分级管理、维护、监控、扩展等
高并发场景下,垂直切分一定程度的提升 IO、数据库连接数、单机硬件资源的瓶颈
垂直切割缺点
部分表无法 join,只能通过接口聚合方式解决,提升了开发的复杂度
分布式事务处理复杂
依然存在单表数据量过大的问题(需要水平切分)
分库分表带来的问题
事务一致性问题
分布式事务
当更新内容同时分布在不同库中,不可避免会带来跨库事务问题。跨分片事务也是分布式事务,没有简单的方案,一般可使用”XA 协议”和”两阶段提交”处理。
分布式事务能最大限度保证了数据库操作的原子性。但在提交事务时需要协调多个节点,推后了提交事务的时间点,延长了事务的执行时间。导致事务在访问共享资源时发生冲突或死锁的概率增高。随着数据库节点的增多,这种趋势会越来越严重,从而成为系统在数据库层面上水平扩展的枷锁。
最终一致性
对于那些性能要求很高,但对一致性要求不高的系统,往往不苛求系统的实时一致性,只要在允许的时间段内达到最终一致性即可,可采用事务补偿的方式。与事务在执行中发生错误后立即回滚的方式不同,事务补偿是一种事后检查补救的措施,一些常见的实现方法有:对数据进行对账检查,基于日志进行对比,定期同标准数据来源进行同步等等。事务补偿还要结合业务系统来考虑。
跨节点关联查询 join 问题
切分之前,系统中很多列表和详情页所需的数据可以通过 sql join 来完成。而切分之后,数据可能分布在不同的节点上,此时 join 带来的问题就比较麻烦了,考虑到性能,尽量避免使用 join 查询。
解决这个问题的一些方法:
- 全局表
全局表,也可看做是”数据字典表”,就是系统中所有模块都可能依赖的一些表,为了避免跨库 join 查询,可以将这类表在每个数据库中都保存一份。这些数据通常很少会进行修改,所以也不担心一致性的问题。
- 字段冗余
一种典型的反范式设计,利用空间换时间,为了性能而避免 join 查询。例如:订单表保存 userId 时候,也将 userName 冗余保存一份,这样查询订单详情时就不需要再去查询”买家 user 表”了。
但这种方法适用场景也有限,比较适用于依赖字段比较少的情况。而冗余字段的数据一致性也较难保证,就像上面订单表的例子,买家修改了 userName 后,是否需要在历史订单中同步更新呢?这也要结合实际业务场景进行考虑。
- 数据组装
在系统层面,分两次查询,第一次查询的结果集中找出关联数据 id,然后根据 id 发起第二次请求得到关联数据。最后将获得到的数据进行字段拼装。
跨节点分页、排序、函数问题
跨节点多库进行查询时,会出现 limit 分页、order by 排序等问题。分页需要按照指定字段进行排序,当排序字段就是分片字段时,通过分片规则就比较容易定位到指定的分片;当排序字段非分片字段时,就变得比较复杂了。需要先在不同的分片节点中将数据进行排序并返回,然后将不同分片返回的结果集进行汇总和再次排序,最终返回给用户.
在分库分表环境中,由于表中数据同时存在不同数据库中,主键值平时使用的自增长将无用武之地,某个分区数据库自生成的 ID 无法保证全局唯一。因此需要单独设计全局主键,以避免跨库主键重复问题。有一些常见的主键生成策略:
全局主键避重问题
1)UUID
UUID 标准形式包含 32 个 16 进制数字,分为 5 段,形式为 8-4-4-4-12 的 36 个字符,例如:550e8400-e29b-41d4-a716-446655440000
UUID 是主键是最简单的方案,本地生成,性能高,没有网络耗时。但缺点也很明显,由于 UUID 非常长,会占用大量的存储空间;另外,作为主键建立索引和基于索引进行查询时都会存在性能问题,在 InnoDB 下,UUID 的无序性会引起数据位置频繁变动,导致分页