
前言
HashMap 在多线程环境下存在线程安全问题,一般在多线程的场景,我都会使用好几种不同的方式去代替:
- 使用
Collections.synchronizedMap(Map)创建线程安全的map集合; HashtableConcurrentHashMap
但是仔细研究过源码的同学都知道,前两者保证线程安全的操作 synchronized 修饰方法,锁住整个 hash 表,效率低下。
ConcurrentHashMap 对锁的粒度和锁的方式进行了优化,jdk1.7 采用了分段锁,将容器的数据分段存储,每一段数据分配一个 Segment,当线程占用一个 Segment 时,其他线程可以访问其他段的数据。
数据结构
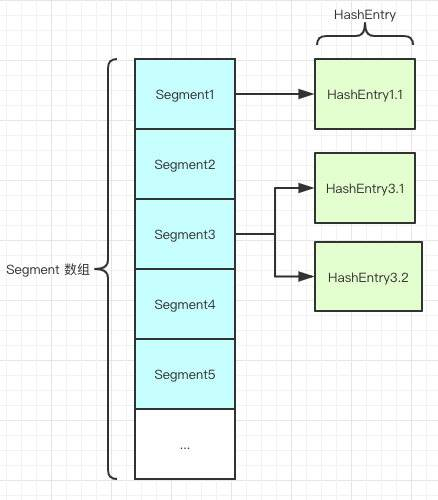
是由 Segment 数组、HashEntry 组成,和 HashMap 一样,仍然是 数组加链表。
CurrentHashMap 包含一个 Segment数组,每个 Segment 包含一个HashEntry 数组并且守护它。
Segment 类继承于 ReentrantLock 类,从而使得 Segment 对象能充当锁的角色。
当修改 HashEntry 数组数据时,需要先获取它对应的 Segment 锁;而 HashEntry 数组采用开链法处理冲突,所以它的每个 HashEntry 元素又是链表结构的元素。
HashEntry跟在HashMap中差不多,但是不同点是,他使用volatile去修饰了他的数据Value还有下一个节点next。保证了内存可见性,所以每次获取时都是最新值。ConcurrentHashMap 的 get 方法是非常高效的,因为整个过程都不需要加锁。
如图:
需知
初始默认容量16,可以自定义,最终计算为2的幂。
初始默认分段数量16,无法扩容,可以自定义,最终计算为2的幂。
默认负载因子大小 0.75
最大容量 1<<30
最大分段数量 1<<16。
每个 segment 分段中哈希表的最小容量2
最大分段数量 1<<16
containsValue 方法不锁表的情况下尝试的次数 2
注:默认构造函数会初始化一个segment数组大小为16的hashMap,并初始化一个hashEntry[]容量为2的segment,其他的segment延迟初始化。
segment:
1 | static final class Segment<K,V> extends ReentrantLock implements Serializable { |
hashEntry:
1 | static final class HashEntry<K,V> { |
hash方法
4次key的hashCode与16位右移异或得到hash值
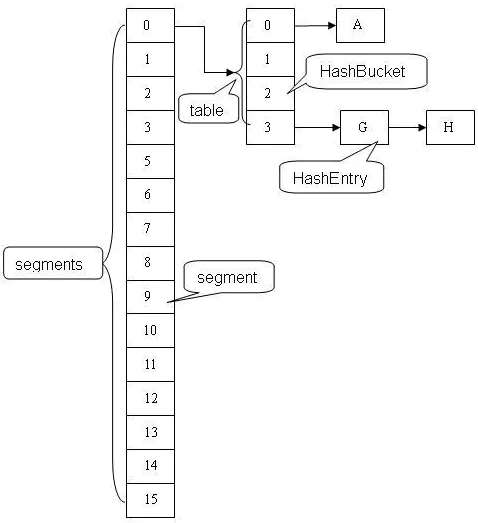
计算 Segment 下标:
(hash >>> segmentShift) & segmentMask 计算 HashEntry 数组下标:
(tab.length - 1) & hash定位segment
首先对 key 的 hashCode 进行 hash 操作
运用散列算法定位 segment 的位置
segmentMask:段掩码,假如 segments 数组长度为 16,则段掩码为 16-1=15;segments 长度为 32,段掩码为 32-1=31。这样得到的所有 bit 位都为 1,可以更好地保证散列的均匀性segmentShift:2 的 sshift 次方等于 ssize,segmentShift=32-sshift。若 segments 长度为 16,segmentShift=32-4=28;若 segments 长度为 32,segmentShift=32-5=27。
而计算得出的 hash 值最大为 32 位,无符号右移 segmentShift位,则意味着只保留高几位(其余位是没用的),然后与段掩码 segmentMask 位运算来定位 Segment。
用Unsafe类的原子操作找到Segment数组中j下标的 Segment 对象(segment为空的,需要初始化)。
1 | int hash = hash(key); |
put
先尝试获取锁,如果加锁(Segment继承ReentrantLock,尝试获取独占锁)失败,则 scanAndLockForPut 自旋等待。
获取锁之后,根据key计算出在数组中的定位,
新增或变更节点,超出最大阈值则 rehash。
scanAndLockForPut
该方法先计算 hash 值在 table 中的位置,循环该位置上的链表查找 key 值。如果不存在则新建节点。
之后尝试加锁 MAX_SCAN_RETRIES 次,如果一直失败则改为阻塞锁获取,保证能获取成功。
期间如果链表头被修改,则重新开始该过程,主要为了在等待锁的过程中预知key。
rehash
对当前 segment的
table进行扩容操作,每个Segment只管它自己的扩容,大小变为原来的 2 倍,其中的元素会被重新分配位置。oldTable[idx]上的链表上的元素可能会重新hash到newTable[idx]和newTbale[idx+n]的链表上,n为oldTable的大小。其实扩容时 hash 值并没有重新计算,变化的只是它们所在的下标而已。
get
首先找到对应的segment
然后找到segment中对应HashEntry链表
遍历链表即可
注:由于hashEntry的value和指向下一个节点的元素用volatile修饰,所以在整个segment内部的操作不用加锁,效率很高。
remove
先尝试获取锁,如果加锁失败,则 scanAndLock 自旋等待(和上面的 put 方法相似)。
获取锁之后,(tab.length - 1) & hash 计算删除节点在 table 中的下标,如果 table 中该位置的链表不为空,循环判断链表中节点是否和删除节点相等(value 为 null 时,key 相等即可,否则 key 和 value 均需相等)。
如果删除节点存在,设置 pre 节点的 next 指针指向 next 节点即可。
size
并发情况下,有可能在统计期间,数组元素个数不停的变化,而且,整个表还被分成了 N个 Segment,怎样统计才能保证结果的准确性呢?
1、第一种方案他会使用不加锁的模式去尝试多次计算ConcurrentHashMap的size,最多三次,比较前后两次计算的结果,结果一致就认为当前没有元素加入,计算的结果是准确的
2、第二种方案是如果第一种方案不符合,他就会给每个Segment加上锁,然后计算ConcurrentHashMap的size返回
1.7 的问题
底层基本上还是数组加链表的方式,我们去查询的时候,还得遍历链表,会导致效率很低。
虽然分段加锁,但锁粒度还是有些高。