
链表介绍
链表通过指针将一组零散的内存块串联在一起。其中,我们把内存块称为链表的“结点”。每个链表的结点除了存储数据之外,还需要记录链上的下一个结点的地址。
单链表
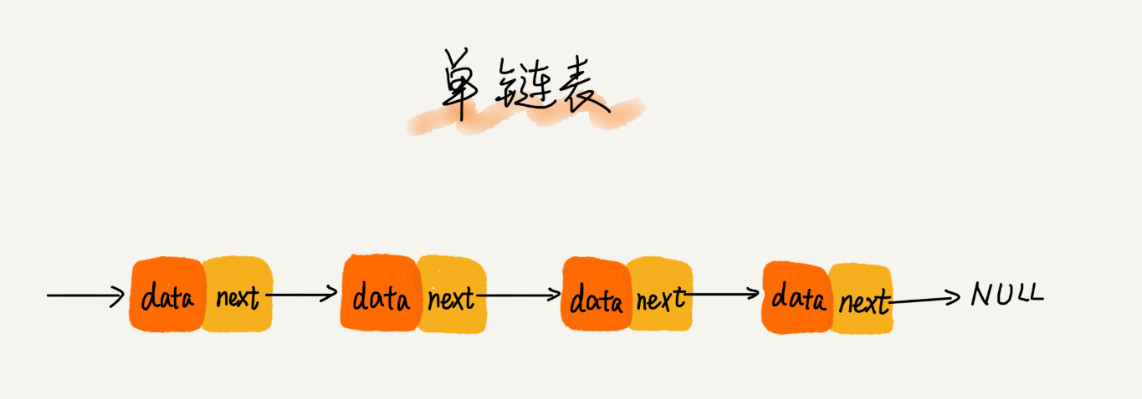
链表有一个头指针指向链表的第一个节点,最后一个节点指向空。
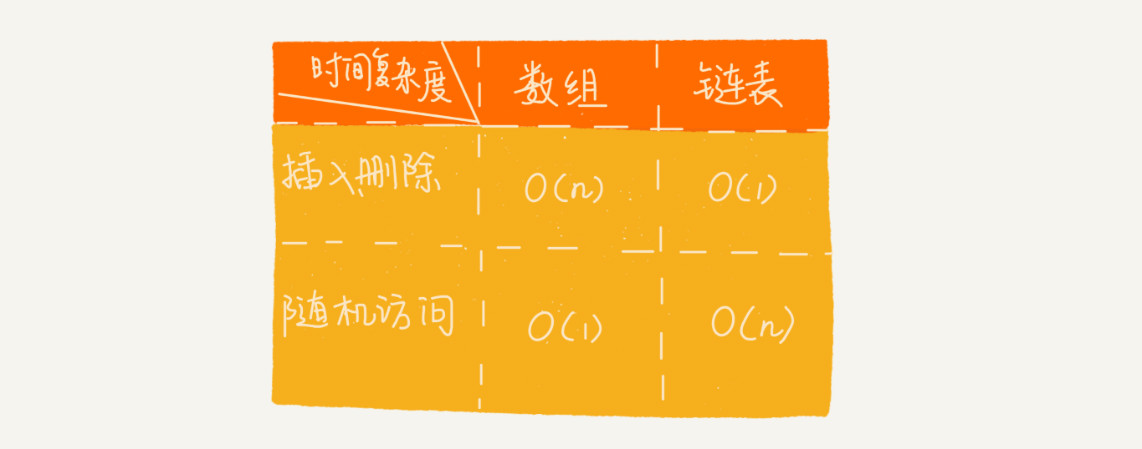
针对链表的插入和删除操作,我们只需要考虑相邻结点的指针改变,所以对应的时间复杂度是 O(1)。
链表要想随机访问第 k 个元素,就没有数组那么高效了。因为链表中的数据并非连续存储的,需要根据指针一个结点一个结点地依次遍历,直到找到相应的结点。
循环链表
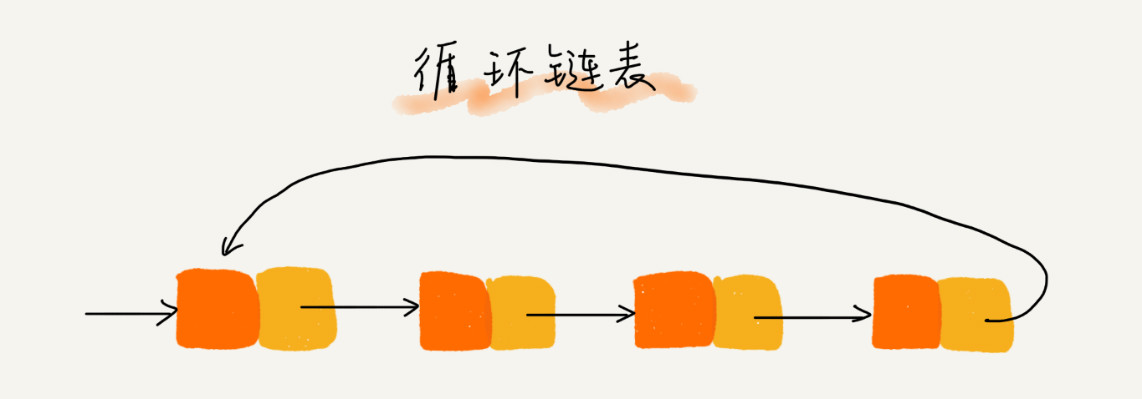
循环链表的尾结点指针是指向链表的头结点。
循环链表的优点是从链尾到链头比较方便。当要处理的数据具有环型结构特点时,就特别适合采用循环链表。
双向链表
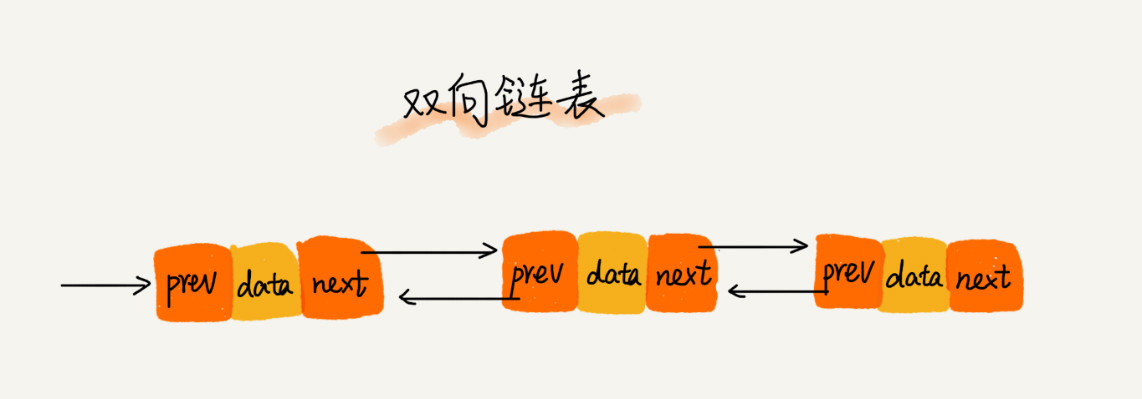
双向链表需要额外的两个空间来存储后继结点和前驱结点的地址。所以,如果存储同样多的数据,双向链表要比单链表占用更多的内存空间。虽然两个指针比较浪费存储空间,但可以支持双向遍历。
从结构上来看,双向链表可以支持 O(1) 时间复杂度的情况下找到前驱结点,正是这样的特点,也使双向链表在某些情况下的插入、删除等操作都要比单链表简单、高效。
对于一个有序链表,双向链表的按值查询的效率也要比单链表高一些。因为,我们可以记录上次查找的位置 p,每次查询时,根据要查找的值与 p 的大小关系,决定是往前还是往后查找,所以平均只需要查找一半的数据。
数组与链表
数组的缺点是大小固定,一经声明就要占用整块连续内存空间。如果声明的数组过大,系统可能没有足够的连续内存空间分配给它,导致“内存不足(out of memory)”。
当我们往支持动态扩容的数组中插入一个数据时,如果数组中没有空闲空间了,就会申请一个更大的空间,将数据拷贝过去,而数据拷贝的操作是非常耗时的。
如果你的代码对内存的使用非常苛刻,那数组就更适合你。因为链表中的每个结点都需要消耗额外的存储空间去存储一份指向下一个结点的指针,所以内存消耗会翻倍。而且,对链表进行频繁的插入、删除操作,还会导致频繁的内存申请和释放,容易造成内存碎片,如果是 Java 语言,就有可能会导致频繁的 GC(Garbage Collection,垃圾回收)。